This topic specifically applies to Snowflake, since Snowflake is a best-of-breed tool for data storage and processing which we can take advantage of through the DSS platform.
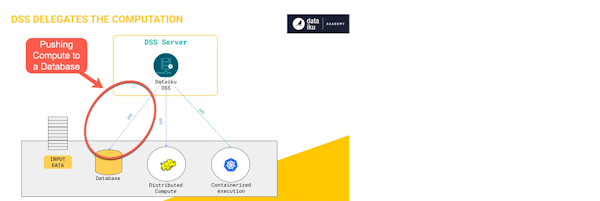
Generally, when we’re referring to the term “pushdown compute”, we’re talking about the ability to process data using an engine other than your Dataiku server. This could be done in a Hadoop or Spark cluster, or in this example, a Snowflake database. More information on the pushdown topic and alternative engines can be found at this link from Dataiku.
In this section, we’ll be discussing many of the reasons why pushdown compute is so beneficial and why Snowflake is such a great database to use for pushdown computation.
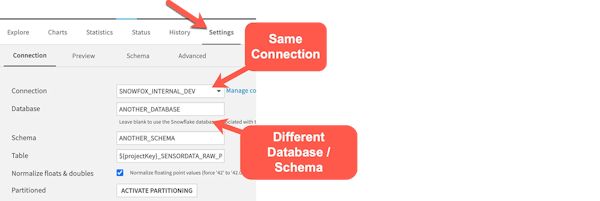
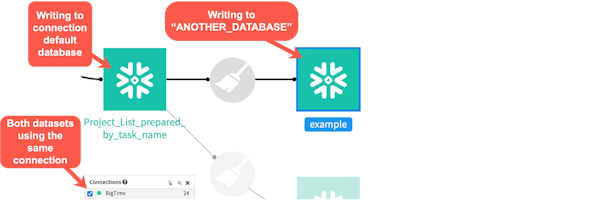
If you’ve used visual recipes in Dataiku, it’s very likely that you’ve already made use of its pushdown compute capabilities. Anytime you’re using an out-of-the-box Dataiku visual recipe that has an input dataset through a database connection (say MS-SQL or Snowflake) and an output dataset in the same connection, Dataiku will default to pushdown if possible. This means that the processing being performed in your recipe will run in that database instead of using your Dataiku server’s resources to perform the operation.